
一、构建本地私有知识库的基本步骤
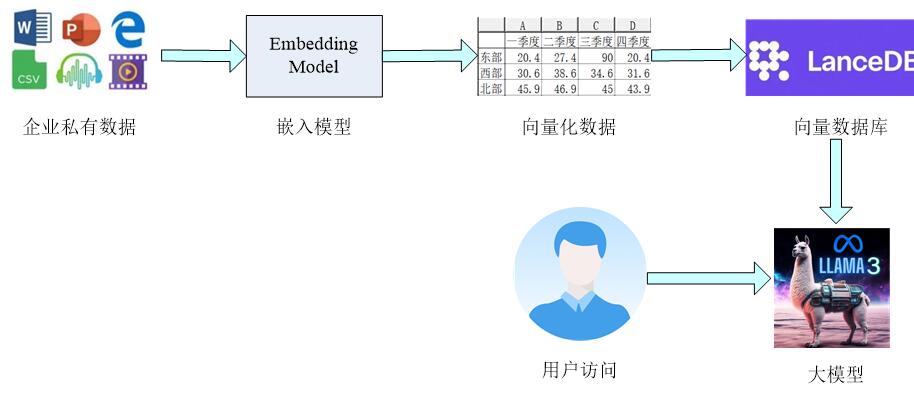
1、整理出需要模型分析的私有数据,比如文本数据(doc、csv、ppt),音视频数据,甚至一些网址链接。
2、通过一个嵌入模型将这些信息转换成模型能够看得懂的向量信息,即信息的向量化。
3、将向量化的信息存储到专属的向量数据库中,构建本地知识库。
当用户提问时,引入的通用大模型将会结合本地知识库中所存在的信息有针对性的回答,可以专门分析本地知识库中的信息来输出。
 二、本地AI知识库的安装和配置
二、本地AI知识库的安装和配置
构建本地知识库工具:AnythingLLM,能够直接读取文档并处理大量信息资源,包括文档上传、自动抓取在线文档,然后进行文本的自动分割、向量化处理,以及实现本地检索增强生成(RAG)等功能。支持几乎所有的主流大模型和多种文档类型,可定制化程度高,安装设置简单,其他工具:还有MaxKB、RAGFlow、FastGPT、Dify 、Open WebUI 等。
1、下载并安装Ollama(用于下载各类通用大模型)
选择所需版本,进行下载。

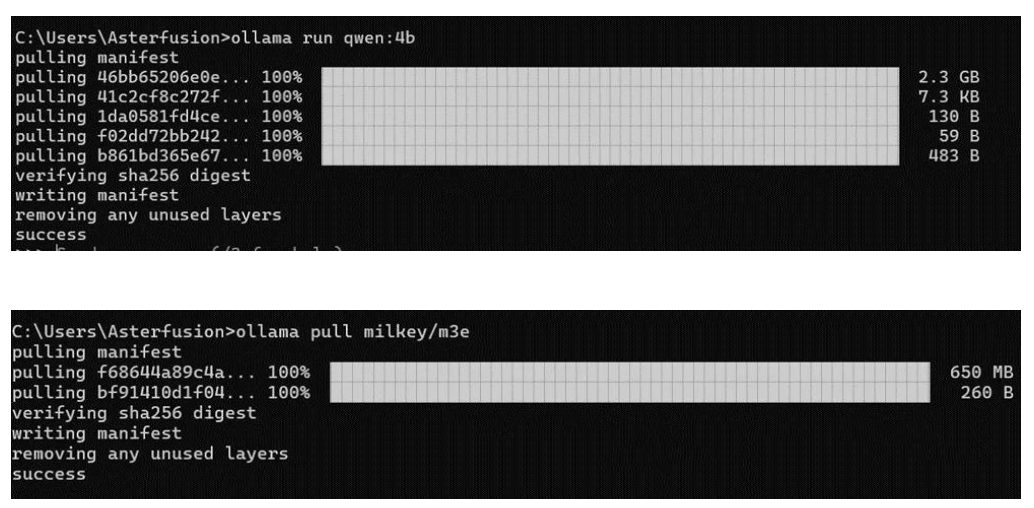
2、安装大模型和嵌入模型
以通义千问大模型和M3e嵌入模型为例,也可以根据自己的需要选择其他模型下载。
3、下载并安装AnythingLLM
选择所需版本,进行下载。
4、配置AnythingLLM
配置参数选择Ollama。
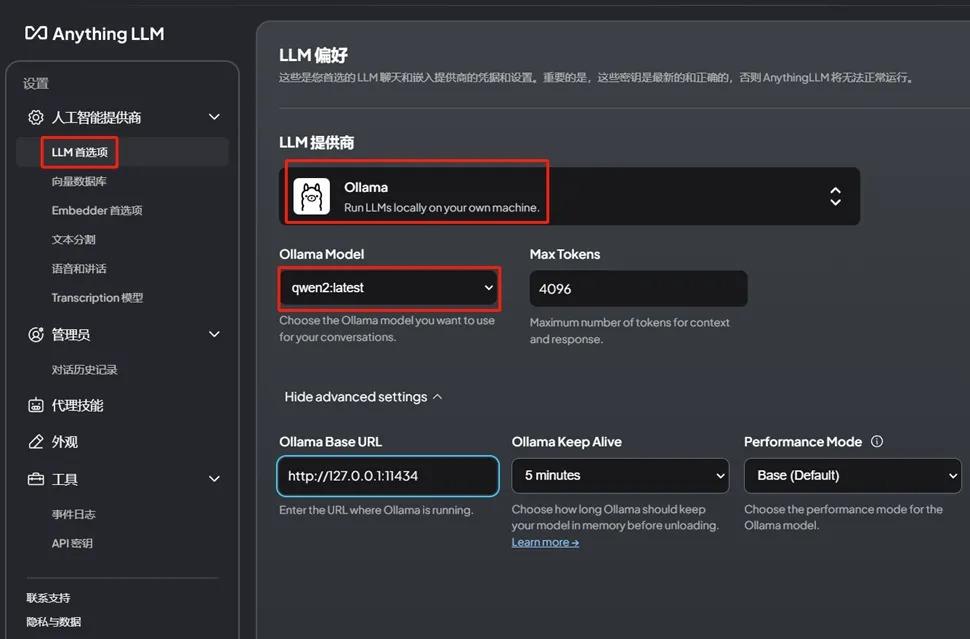
Embedder选择M3e。
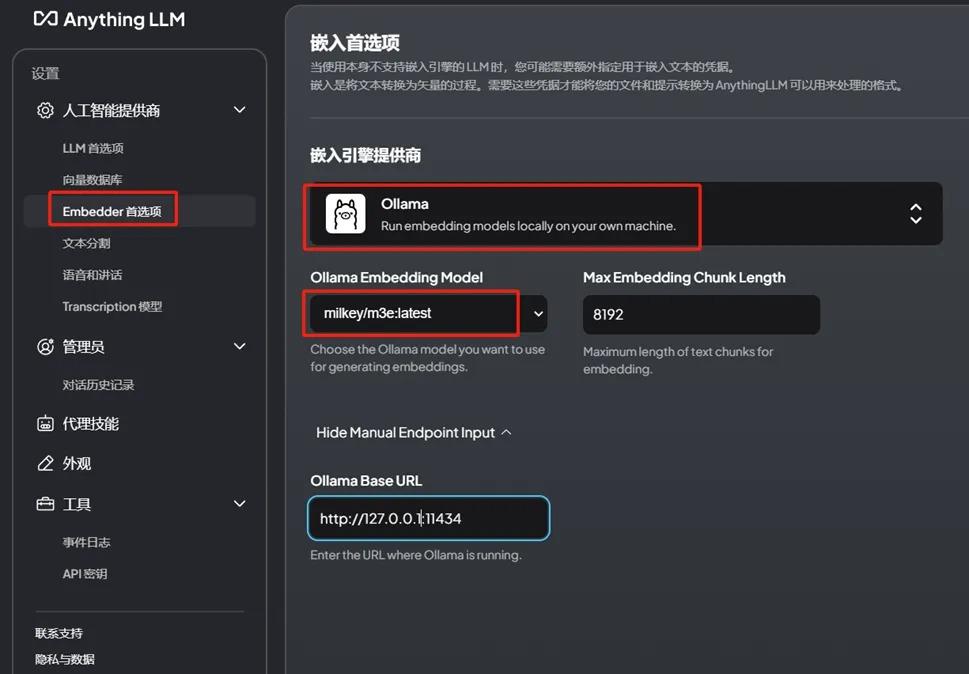
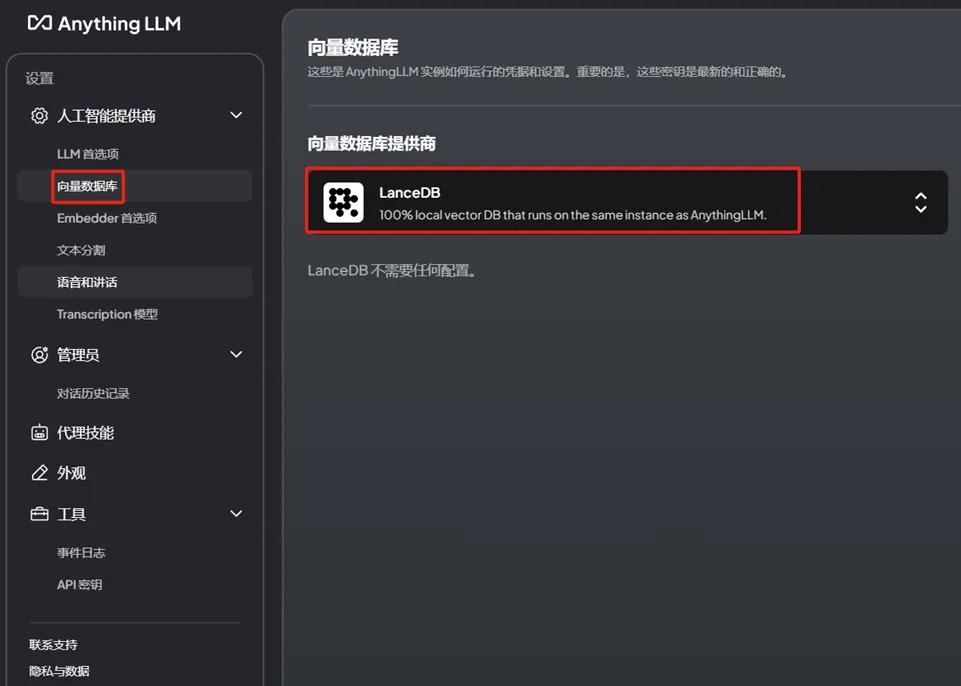
向量数据库选择LanceDB(默认)。
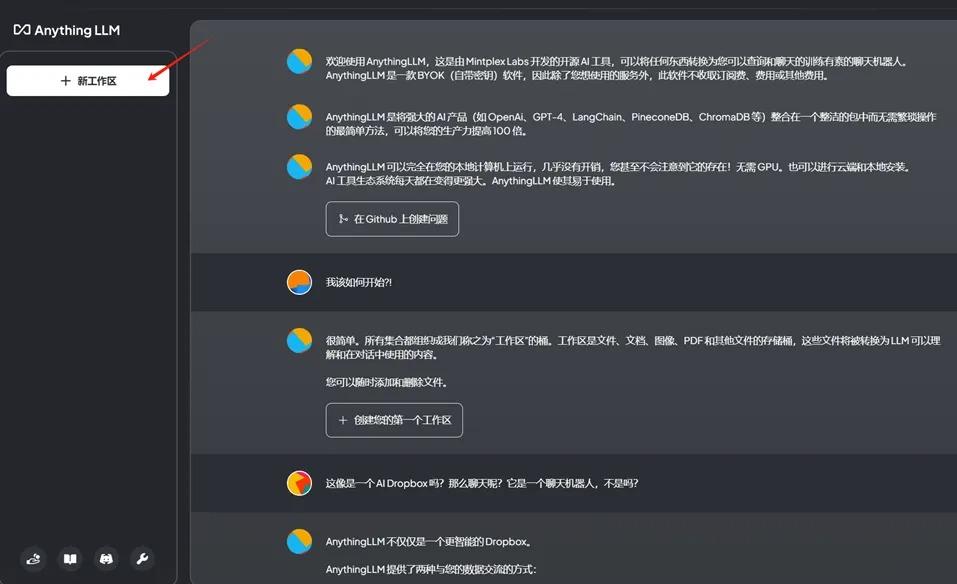
5、上传私有数据并验证AI问答效果
创建工作区,上传各种文档格式的企业私有数据,验证是否能正常工作。
本地AI知识库已经在利用上传的私有文本数据回答问题了,下一步需要持续不断地丰富私有内容,让其更加智能、可靠。